

Reliable concept drift detection models are required to monitor AI systems, especially high-risk ones, adequately. As we elaborated in our last article, current concept drift detection methods are not ideal for working with complex data streams, such as images in a visual quality assurance system. Most methods and tools focus on cases with existing ground truth labels – but in many real-life scenarios, you don’t have access to such labels, at least not without any additional effort. So, are there other options?
How Anomaly Detection Works as a Concept Drift Trigger
Let’s take a step back and think about the underlying problem we want to solve. The goal is to have an ideally universal method to detect changes in input data to know when to retrain a model. In our previous article, we established that labels are oftentimes not available or very expensive to generate. This means we should focus on unsupervised methods if we want to solve our concept drift problems universally.
Unsupervised Anomaly Detection Without Labels
So, what are unsupervised methods in the literature trying to achieve? They want to compare the current distribution of samples with a reference distribution, for example, the distribution during training. If we think about this problem on the level of single samples we can find astonishing similarities to out-of-distribution detection (aka anomaly detection).
In out-of-distribution detection, the goal is to identify single instances that do not belong to the initial training distribution. This field is extensively studied in a wide range of use cases, and methods from this field are widely deployed in real-life use cases. Methods in this domain return a single value: an out-of-distribution score that aims to represent how far the data sample is from the initial training distribution.
We can interpret the average out-of-distribution values over a sliding window of samples from a data stream as the distance of the data distribution in the detection window to the training distribution of the anomaly detection model. Therefore, running an anomaly detection model on a stream of data and looking at the running mean over its anomaly scores represents two parts of a general concept drift detector. It models the data and calculates the distance between the two distributions.
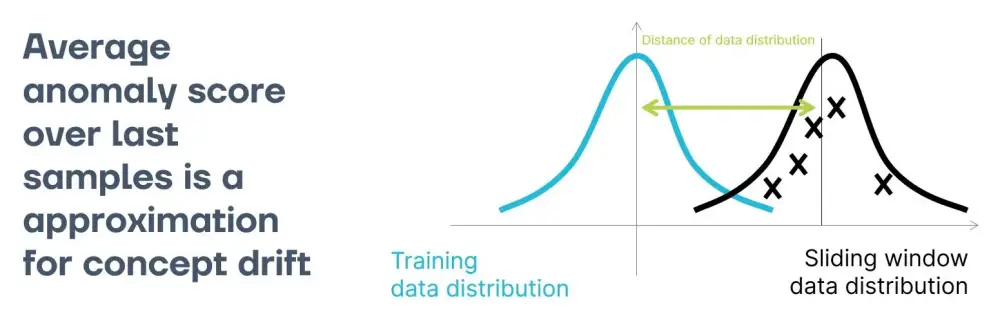
It is reasonable to utilize the capability of out-of-distribution models to assess the distance of a novel sample to the initial training distribution because they are widely used and heavily researched. Consequently, the average of out-of-distribution scores should represent a meaningful measure of how far the data has drifted. This idea is strengthened by the fact that some approaches such as FAAD and STUDD take inspiration from anomaly detection. However, the idea that anomaly detection models do a good job at detecting concept drift has yet to be explored in the literature.
Testing Anomaly Detection Models as Concept Drift Detector
That was the theory, but is our hypothesis true in practice? But is our hypothesis true? Are anomaly detection methods suitable as concept drift detectors? We decided to explore this question during our internal hackathon. To do so, we chose a set of methods to compare and a benchmark to test it. Being bound by time, we went for simple approaches.
A Synthetic Dataset as Concept Drift Benchmark
Current literature indicates a lack of real-life datasets to benchmark concept drift detectors. With our limited time in mind, we decided to build our own synthetic dataset. For this, we need to implement a dataset that allows us to introduce concept drift arbitrarily. As there is a large gap in concept drift detectors for computer vision tasks, we select the commonly used MNIST datasetas our base. Then, we introduce two variables that help us control concept drift in our data. Severeness level (values from 0 to 10) and probability of concept drift. Based on these variables we used the following transformations:
- transforms.RandomErasing(p=1, scale=(0.001, max(1, severeness)/100))
- transforms.RandomPerspective(distortion_scale=severeness/20, p=0.1),
- transforms.RandomRotation((-severeness*3, severeness*3)),
- transforms.GaussianBlur(kernel_sizes[int(severeness/10)], sigma=(0.1, 2.0))
- transforms.RandomResizedCrop((28,28), scale=((min(1,5/max(severeness,1))), 1.0)),
- torch.rand(28,28)*(1+self.test_concept_drift_severeness/40) #Random Noise and clip
These transformations are applied based on the probability defined in the probability attribute. The following figure shows a visualization of the resulting samples. The goal of this approach is to simulate a deteriorating camera.

The next step is to train an MNIST classifier. For this purpose, we use PytorchLightning and a trivial neural network with dropout. We train our classifier for 5 epochs with a training validation split of 55k training samples and 5k validation samples which achieves a validation accuracy of ~95%.
Does the Simulated Concept Drift Affect Performance?
Let’s continue by exploring the effect of introducing different levels of concept drift on the performance of our classification model.

As expected, we can see that increasing the concept drift reduces the accuracy of the MNIST Classifier. Increasing the severeness of the concept drift directly leads to worse performance.
Anomaly Detection Algorithms
Time to implement the concept drift detection algorithms! We will implement four different approaches based on recent findings in the literature. First, we take advantage of the model’s uncertainty to detect concept drift, inspired by Baier et al, which use softmax entropy for this purpose. Additionally, we implement their Monte-Carlo-Dropout-based approach and a simple Autoencoder as our baseline Anomaly Detection model. As a fourth approach, we implement a recent well-performing Rotation Prediction Anomaly Detection Model based on RotNet.
How Do the Different Anomaly Detection Algorithms Perform?
Finally, we run our model on the test set 11 times each time, increasing the severeness of the concept drift each time. Then, we measure the arithmetic mean accuracy for each batch and plot it next to the concept drift values detected by our approaches. Also, we use sliding window sizes of 50, and 150 samples for our concept drift detection approaches. Note that we scaled the outputs of all methods to a range from 0 to 1 to make them more visually comparable.
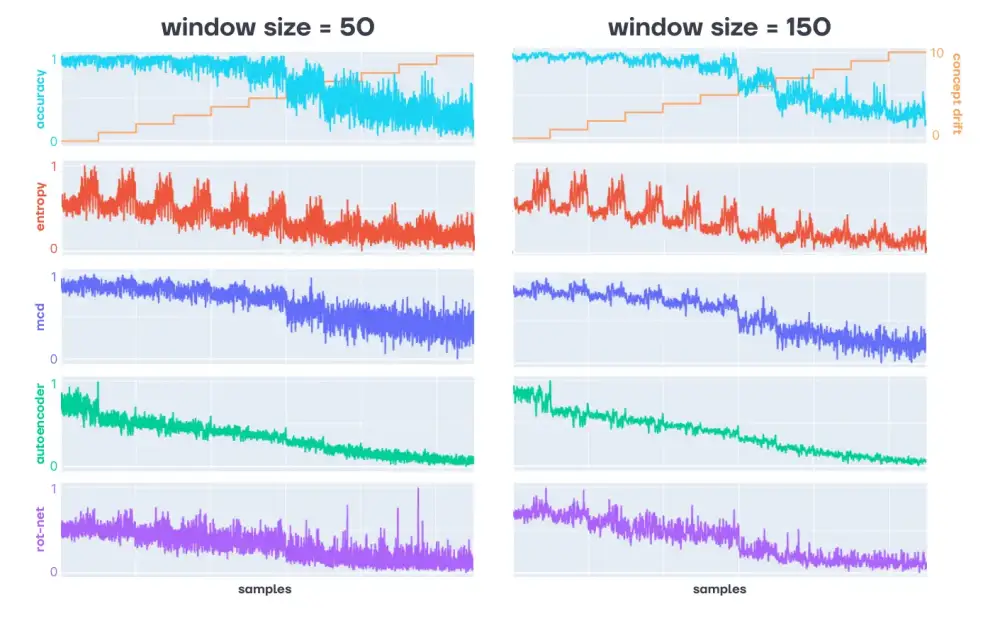
The first thing that can be easily observed is that, no matter the approach, the concept drift mimics the actual concept drift and, analogously, the model’s performance. This indicates thatany of these approaches would already provide value when no supervised options for drift detection are available. While more rigorous testing will be needed, these plots already indicate that some methods might be more appropriate than others in real-world scenarios:
- Entropy-Based Approach: You can see, that the entropy-based approach has a larger variance, making it harder to determine thresholds that trigger a warning.
- Monte-Carlo-Dropout-Based Approach: Compared to the entropy-based approach, the Monto-Carlo-Dropout-based approach (mcd) already works better and mimics the accuracy rather closely.
- Autoencoder-Based Approach: The autoencoder-based method seems to mimic the linear increase in concept drift even more closely and has a significantly smaller variance, particularly for smaller window sizes. Thus, it might give a better understanding of the underlying change in the data distribution and be better suitable to trigger warnings.
- Rotation-Based Approach: Finally, the rotation-based anomaly detection model follows a logarithmic scale (which we accounted for during scaling) and shows strong signals for larger concept drifts. This can probably be attributed to the fact that we used rotation as one of our augmentations in generating concept drift. Therefore, the rotation prediction model is understandably confident at predicting the wrong orientation in cases of larger image rotations. This might be an exciting property in cases where monitoring concept drift of a particular kind is of special interest.
Our Conclusion
To find an approach for detecting concept drift during model monitoring which doesn’t depend on ground truth labels, we suggest taking inspiration from the very active and mature research field of out-of-distribution (aka. anomaly detection) detection. Due to their capacity to measure the “out-of-distributionness” of single samples, they are also fit to asses distribution shifts over time.
While our experiments here are quite rudimentary, we got indications that our proposition might hold and that anomaly detection models could be good at detecting concept drift. We saw that anomaly detection models based on Monte Carlo Dropout, as well as the autoencoder and rotation-prediction-based approaches, are able to detect concept drift. In this case, the autoencoder approach provided the most promising results.
Using anomaly detection models for concept drift detection is a promising direction for future work and might help making AI-powered systems more reliable in the future.








